iPhone 17 Pro: το πρώτο με chipset που βασίζεται στη διαδικασία 2nm της TSMC

Σύμφωνα με ανακοίνωση της TSMC το πρώτο iPhone που θα διαθέτει chipset κατασκευασμένο στη διεργασία 2nm της TSMC, θα είναι το iPhone 17 Pro του επόμενου έτους. Ήδη έχουν αρχίσει οι εργασίες σε μια διαδικασία 2nm το 2022 και το αποτέλεσμα θα είναι πρωτίστως η παραγωγή σε μικρή κλίμακα, ενώ η μαζική παραγωγή θα ξεκινήσει το 2025, έγκαιρα ώστε να κυκλοφορήσει το iPhone 17 Pro το φθινόπωρο του επόμενου έτους. Θα ακολουθήσει μια βελτιωμένη έκδοση της διεργασίας των 2nm, στα τέλη του 2026, και μετέπειτα, όπως φημολογείται, άλμα στα 1,4nm. Έχει επίσης υποστηριχθεί ότι η Apple είχε συνάψει σύμβαση για την όλη διαδικασία 2nm της TSMC. Εκτός από το iPhone 17 Pro, τα τσιπ των 2nm ενδέχεται να χρησιμοποιηθούν και στα μελλοντικά Apple Silicon Macs. Σημειώνεται ότι η σειρά iPhone 16 και το iOS 18 αναμένεται με μεγάλη έμφαση στην τεχνητή νοημοσύνη, ωστόσο, η διεξοδικότερη επεξεργασία που απαιτείται για τη συσκευή, δεν θα έχει ακόμη για φέτος τα αναμενόμενα αποτελέσματα.
Τα τρένα του Σαν Φρανσίσκο θα λειτουργούν με δισκέτες 5,25 ινστών μέχρι το 2030

Τα ΜΜΜ του Σαν Φρανσίσκο (SFMTA) είχαν εισάγει τις δισκέτες 5.25 ιντσών ήδη από το 1998, ως τμήμα των συστημάτων αυτοματισμού (ATCS) των τρένων που ελέγχει τα συστήματα φρένων και τους τοπικούς servers και σύμφωνα με ανακοίνωσή τους θα συνεχίσουν να τις αξιοποιούν για 6 χρόνια ακόμη! Οι δισκέτες φέρουν το λογισμικό των κεντρικών servers και σύμφωνα με εκπρόσωπο του δικτύου «όταν ένα τρένο μπει κάτω από την επιφάνεια της γης μπαίνει στο automatic mode, όπου είναι αυτόνομο και ο οδηγός απλά επιβλέπει. Όταν βγει από τον υπόγειο, αποσυνδέεται από το ATCS και επιστρέφει στη χειροκίνητη λειτουργία». Η απομάκρυνσή τους αν και είχε προγραμματιστεί από το 2018 με στόχο ολοκλήρωσης τη δεκαετία, η καταληκτική ημερομηνία μετά την COVID-19 παρατάθηκε για το 2029-2030. Ας σημειωθεί ότι το προσδόκιμο του συστήματος αυτοματισμών των τρένων θα ολοκληρωνόταν το 2023, αφού είχε προγραμματιστεί να λειτουργήσει για 20-25 χρόνια. Αξίζει επίσης να σημειωθεί ότι, σύμφωνα πάντα με την εταιρεία, είναι και δύσκολο να βρει κανείς προσωπικό που να κατανοεί τον τρόπο λειτουργίας αυτών των απαρχαιωμένων συστημάτων. Το 2020, μάλιστα, το σύστημα αυτοματισμών χρησιμοποιούσε δισκέτες 5.25 ιντσών που «έτρεχαν» προγράμματα σε περιβάλλον DOS!
Η τεχνητή νοημοσύνη του Rakuten Viber κάνει περίληψη συνομιλίες ομαδικών σε χρόνο «μηδέν»
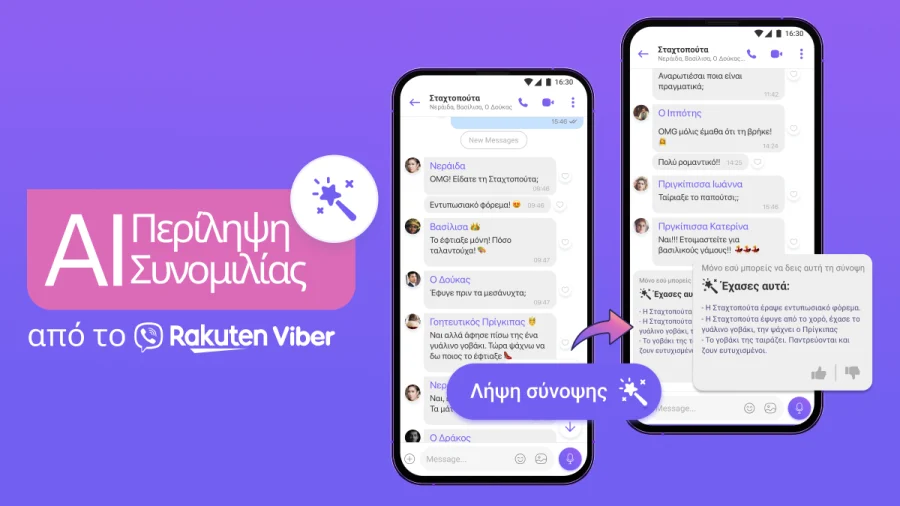
Εκμεταλλευόμενη την τεχνολογία πίσω από το ChatGPT, συνοψίζει μεγάλες συζητήσεις σε τίτλους, ώστε να μη χάνεται η σημαντική πληροφορία. Tο Rakuten Viber, η κορυφαία εφαρμογή για ασφαλή και ιδιωτική επικοινωνία μέσω μηνυμάτων και φωνής, εκμεταλλεύεται την τεχνολογία του OpenAI για να δημιουργήσει μια λειτουργία τεχνητής νοημοσύνης που προσφέρει περίληψη συνομιλιών για μη αναγνωσμένα μηνύματα σε ομαδικές συνομιλίες. Αναπτυγμένη για να ικανοποιήσει τις ανάγκες εκατομμυρίων απασχολημένων χρηστών, αυτή η προηγμένη λύση προσφέρει έναν ομαλό και γρήγορο τρόπο να συνοψίζονται οι βασικές πληροφορίες από έως και 100 μη αναγνωσμένα μηνύματα σε μια συνομιλία και να παρουσιάζονται με συνοπτικό τρόπο. Η λειτουργία περίληψης μέσω τεχνητής νοημοσύνης εξάγει τα πιο σημαντικά μέρη από τις ομαδικές συνομιλίες ενός χρήστη και, αμέσως, με συντομία, μεταφέρει σε τίτλους τι συζητήθηκε, εξοικονομώντας όχι μόνο χρόνο και ενέργεια, αλλά και βελτιώνοντας τη λήψη αποφάσεων και την παραγωγικότητα. Η άμεση παράδοση της περίληψης βοηθά τους χρήστες να παραμένουν ενήμεροι χωρίς να ξαναμπούν σε μια μακρά συνομιλία που θα χρειαστεί κύλιση της οθόνης ανάμεσα σε πολλά μηνύματα. Εστιάζοντας αρχικά στις ομαδικές συνομιλίες, η λειτουργία περίληψης μέσω τεχνητής νοημοσύνης εξυπηρετεί τη δημοφιλέστερη μορφή επικοινωνίας μεταξύ των χρηστών του Viber. Οι οποίοι πλέον θα μπορούν να βλέπουν συγκεντρωμένες τις πιο σημαντικές αποφάσεις και επιχειρήματα σε μια συζήτηση για βολική ανάγνωση. Φανταστείτε την ευκολία που θα προσφέρει η λειτουργία αυτή στους γονείς που διαχειρίζονται τις σχολικές ή αθλητικές εκδηλώσεις των παιδιών τους μέσω συνεργατικών συζητήσεων, τα μέλη της οικογένειας που σχεδιάζουν ένα πάρτι γενεθλίων για ένα αγαπημένο τους πρόσωπο ή τις ομάδες φίλων που ετοιμάζουν μαζί ένα ταξίδι. Η ενεργοποίηση είναι απλή: οι χρήστες που εισέρχονται σε μια ομαδική συνομιλία με μη αναγνωσμένα μηνύματα θα λάβουν ένα μήνυμα για να λάβουν προαιρετικά μια περίληψη του μέρους της συζήτησης στο οποίο δεν έχουν συμμετάσχει. Είναι σημαντικό να σημειωθεί ότι αυτές οι περιλήψεις είναι ορατές μόνο στους χρήστες που τις ζητούν, εξασφαλίζοντας έτσι την ιδιωτικότητα και την εμπιστευτικότητα. Η ασφάλεια και η προστασία των δεδομένων ήταν οι προτεραιότητες κατά την ανάπτυξη αυτής της λειτουργίας. Το περιεχόμενο περίληψης της συνομιλίας τεχνητής νοημοσύνης δεν περιλαμβάνει κανένα αναγνωριστικό πέρα από τα ονόματα χρηστών, έτσι ώστε συγκεκριμένες συνομιλίες να μην μπορούν να συνδεθούν εξωτερικά με κανένα μέλος ομάδας. Επιπλέον, το Viber δεν έχει πρόσβαση σε ή δεν αποθηκεύει συνομιλίες ή περιλήψεις στους διακομιστές του, δημιουργώντας έτσι μια ασφαλή και ιδιωτική εμπειρία χρήστη. “Αναζητούμε συνεχώς νέους και καινοτόμους τρόπους για να διευκολύνουμε και να απλοποιούμε τη ζωή των χρηστών μας”, δήλωσε ο Ofir Eyal, Διευθύνων Σύμβουλος της Rakuten Viber. “Γι’ αυτό αξιοποιούμε τη δύναμη της γεννητικής τεχνητής νοημοσύνης για να τους εξοικονομήσουμε χρόνο και να βεβαιωθούμε ότι δεν χάνουν καμία σημαντική συνομιλία: Από τους συμμαθητές που συζητούν για προγράμματα σχολείου μέχρι τους φίλους ή την οικογένεια που κάνουν σχέδια για το Σαββατοκύριακο, οι χρήστες μας μπορούν να πάρουν γρήγορα να διαβάσουν οτιδήποτε έχουν χάσει.” Η λειτουργία κυκλοφορεί σταδιακά στους χρήστες στις Ηνωμένες Πολιτείες, τις Φιλιππίνες, την Ουκρανία, την Ιαπωνία, τη Βουλγαρία και την Πολωνία, με περισσότερες χώρες να ακολουθούν σύντομα. Υποστηρίζει τις πλατφόρμες iOS και Android και κατανοεί περισσότερες από 50 γλώσσες. Πηγή: businessnews.gr
Υπό ανάπτυξη AI που εκπαιδεύεται με δεδομένα από πολλές γλώσσες

Ο κορεατικός διαδικτυακός γίγαντας Naver παρουσίασε την περασμένη εβδομάδα μια οικογένεια μεγάλων γλωσσικών μοντέλων με την ονομασία HyperCLOVA X, τα οποία, όπως ισχυρίστηκε, αποδίδουν καλύτερα στη διαγλωσσική συλλογιστική σε ασιατικές γλώσσες από άλλα μοντέλα και επομένως μπορούν να βοηθήσουν την περιοχή να αναπτύξει κυρίαρχα μεγάλα γλωσσικά μοντέλα. Η Naver ανήγγειλε το ντεμπούτο του HyperCLOVA X στα κορεατικά και παραπέμπει σε μια αγγλόφωνη τεχνική έκθεση στο επιστημονικό περιοδικό arXiv όπου υποστηρίζει το εξής: Πιστεύουμε ότι το HyperCLOVA X, με τις ανταγωνιστικές ικανότητες του στα αγγλικά και σε άλλες γλώσσες πέραν των κορεατικών, μπορεί να παρέχει χρήσιμη καθοδήγηση σε περιοχές ή χώρες για την ανάπτυξη των δικών τους κυρίαρχων LLM. Οι LLMs προ-εκπαιδεύτηκαν σε δεδομένα “που αποτελούνται από κορεατικά και πολύγλωσσα δεδομένα, καθώς και από τμήματα κώδικα”. Το πολύγλωσσο υποσύνολο ήταν κυρίως αγγλικά, αλλά περιλάμβανε επίσης μια ποικιλία άλλων γλωσσών, όπως ιαπωνικά, γερμανικά και γαλλικά. Το κορεατικό γλωσσικό υλικό αποτελούσε περίπου το ένα τρίτο των δεδομένων προ-εκπαίδευσης, μια ένδειξη ότι η Naver επέλεξε να βελτιώσει τις επιδόσεις των μοντέλων της στη μητρική της γλώσσα. Η διαδικασία προ-εκπαίδευσης έλαβε επίσης υπόψη την ιδιαίτερη γραμματική της κορεατικής γλώσσας. Το αποτέλεσμα αυτής της προσπάθειας, διαβεβαιώνει η Naver, είναι μοντέλα “με εγγενή επάρκεια τόσο στην κορεατική όσο και στην αγγλική γλώσσα”. Ακόμα καλύτερα, τα μοντέλα εμφανίζουν “πολυγλωσσία” – την ικανότητα να λειτουργούν σε γλώσσες διαφορετικές από αυτές για τις οποίες εκπαιδεύτηκαν. Η ανάλυση μας δείχνει ότι η HyperCLOVA X δεν είναι μόνο σε θέση να επεκτείνει τη συλλογιστική της ικανότητα πέραν των γλωσσών στις οποίες απευθύνεται κατά κύριο λόγο, αλλά και να επιτύχει το υψηλότερο επίπεδο στη μηχανική μετάφραση μεταξύ της κορεατικής και μη στοχευμένων γλωσσών, όπως η ιαπωνική και η κινεζική. Η εντυπωσιακή πολυγλωσσική ικανότητα της HyperCLOVA X περιλαμβάνει επίσης τη διαγλωσσική μεταφορά μεταξύ κορεατικών και αγγλικών, όπου ο συντονισμός οδηγιών στη μία γλώσσα μπορεί να οδηγήσει στην εμφάνιση δυνατοτήτων παρακολούθησης οδηγιών στην άλλη. Τα αποτελέσματα των πολύγλωσσων δοκιμών οδήγησαν την εταιρεία ανάπτυξης στο συμπέρασμα ότι το HyperCLOVA X “μπορεί να μεταφερθεί σε ασιατικές γλώσσες που υποεκπροσωπούνται στα δεδομένα προ-εκπαίδευσης”. Η ανάπτυξης κυρίαρχης AI αναδύεται ως μια αναγκαία εθνική ικανότητα για κάθε χώρα, ως μέσο εξασφάλισης της ασφάλειας των δεδομένων και μείωσης της εξάρτησης από εξωτερικούς παρόχους. Όπως επισημαίνει η τεχνική έκθεση της Naver, οι αγγλικές και βορειοαμερικανικές κουλτούρες “είναι εξαιρετικά υπερεκπροσωπημένες στα προ-εκπαιδευτικά σώματα” για τα υπάρχοντα καθιερωμένα LLMs. Κατά συνέπεια, αυτά τα LLMs παρουσιάζουν περιορισμούς στην ικανότητα τους να επεξεργάζονται και να κατανοούν μη αγγλικές γλώσσες όπως η κορεατική, η οποία ενσωματώνει ιδιαίτερες πολιτιστικές αποχρώσεις, γεωπολιτικές καταστάσεις και άλλες περιφερειακές ιδιαιτερότητες, καθώς και μοναδικά γλωσσικά χαρακτηριστικά. Εξάλλου, η Κίνα προσπαθεί επίσης να αναπτύξει δικά της LLMs για την εξυπηρέτηση των εθνικών συμφερόντων. AI chatbots όπως το ERNIE της Baidu είχαν συγκεντρώσει πάνω από 100 εκατομμύρια χρήστες μέχρι το τέλος του 2023. Ο Nak-ho-Seon, επικεφαλής της τεχνολογίας Naver Cloud Hyperscale AI, δήλωσε ότι σχεδιάζει “να δημιουργήσει εξειδικευμένες AI σε μεγάλη κλίμακα για διάφορες περιοχές και χώρες στο μέλλον”. Εν τω μεταξύ, η τεχνική έκθεση συμπεριλαμβάνει τη δέσμευση να “εξερευνήσει την πολυτροπικότητα, με στόχο να διευρύνει τις δυνατότητες του HyperCLOVA X να επεξεργάζεται και να ενσωματώνει απρόσκοπτα διάφορους τύπους δεδομένων, όπως κείμενο, εικόνες και ήχο”, ενώ παράλληλα επιδιώκει να βελτιστοποιήσει τις ικανότητες εξαγωγής συμπερασμάτων του μοντέλου. Τέλος, η Naver ισχυρίζεται ότι “ερευνά ενεργά την ενσωμάτωση εξωτερικών εργαλείων και APIs για την ενίσχυση των λειτουργιών του μοντέλου, κάτι που θα επιτρέψει στο HyperCLOVA X να έχει πρόσβαση σε εξειδικευμένα σύνολα δεδομένων και υπηρεσίες”. Πηγή: techgear.gr
41 χρόνια μετά, η Microsoft φέρνει επιτέλους μια βασική λειτουργία στο Σημειωματάριο των Windows!

Κάλλιο αργά παρά ποτέ; Κάτι που ενδεχομένως πολλοί να μη γνωρίζουν είναι πως το Σημειωματάριο των Windows στην πραγματικότητα είναι πιο παλιό και από το ίδιο το λειτουργικό σύστημα! Συγκεκριμένα, το εν λόγω πρόγραμμα της Microsoft έκανε αρχικά την εμφάνισή του στο MS-DOS, μέσα από μια ενημέρωση που έφτασε το 1983, προσθέτοντας υποστήριξη για χρήση ποντικιού. Από τότε είναι ένα αναπόσπαστο κομμάτι όλων των εκδόσεων των Windows, αποτελώντας μέχρι και σήμερα μια γρήγορη, απλή και χωρίς επιπλέον κόστος εναλλακτική για όσους δε θέλουν να γράψουν ή να επεξεργαστούν κάποιο κείμενο χωρίς το Word. Παρόλο που το χρησιμοποιούν όμως εκατομμύρια χρήστες, εδώ και πολλά χρόνια το Σημειωματάριο (Notepad) ήταν πρακτικά παρατημένο, χωρίς να λαμβάνει επιπρόσθετα χαρακτηριστικά ή αλλαγές. Αυτό άλλαξε πρόσφατα, όταν η Microsoft ξεκίνησε να το εκσυγχρονίζει, προσθέτοντας καρτέλες, dark mode λειτουργία και άλλα χαρακτηριστικά. Στο πλαίσιο αυτής της προσπάθειας, η εταιρία έκανε τώρα γνωστό ότι θα φέρει στο Σημειωματάριο και ένα πολύ βασικό χαρακτηριστικό. Ναι, 41 ολόκληρα χρόνια μετά το ντεμπούτο του, το Σημειωματάριο των Windows θα αποκτήσει επιτέλους ορθογραφικό έλεγχο! Σύμφωνα με την σχετική ανάρτηση στο blog του Windows Insider προγράμματος, οι λειτουργίες ορθογραφικού ελέγχου θα δουλεύουν με τον γνωστό τρόπο που όλοι γνωρίζουν. Το λογισμικό θα επισημάνει τα λάθη που εντοπίζει και τις εσφαλμένα γραμμένες λέξεις με μια κόκκινη υπογράμμιση. Φυσικά, θα προσφέρει εναλλακτικές λύσεις με αριστερό κλικ, ενώ ο χρήστης θα έχει τη δυνατότητα να ελέγξει μαζικά όλα τα εντοπισμένα λάθη πατώντας τον συνδυασμό Shift + F10. Για την ώρα η νέα έκδοση του Notepad που προσφέρει και spell check δοκιμάζεται με τα μέλη του Windows Insider προγράμματος και αναμένεται να γίνει ευρέως διαθέσιμη για τους χρήστες των Windows 11 σύντομα. Πηγή: unboxholics.com